/*const int n = 8; int A[n] = {2,5,3,0,2,3,0,3};*/ constint n = 10; int A[n] = {95, 94, 91, 98, 99, 90, 99, 93, 91, 92};
voidfindMaxMinIdx(int &min, int &max){ min = max = 0; for (int i = 1; i < n; ++i) { if (A[min] > A[i]) { min = i; } if (A[max] < A[i]) { max = i; } } }
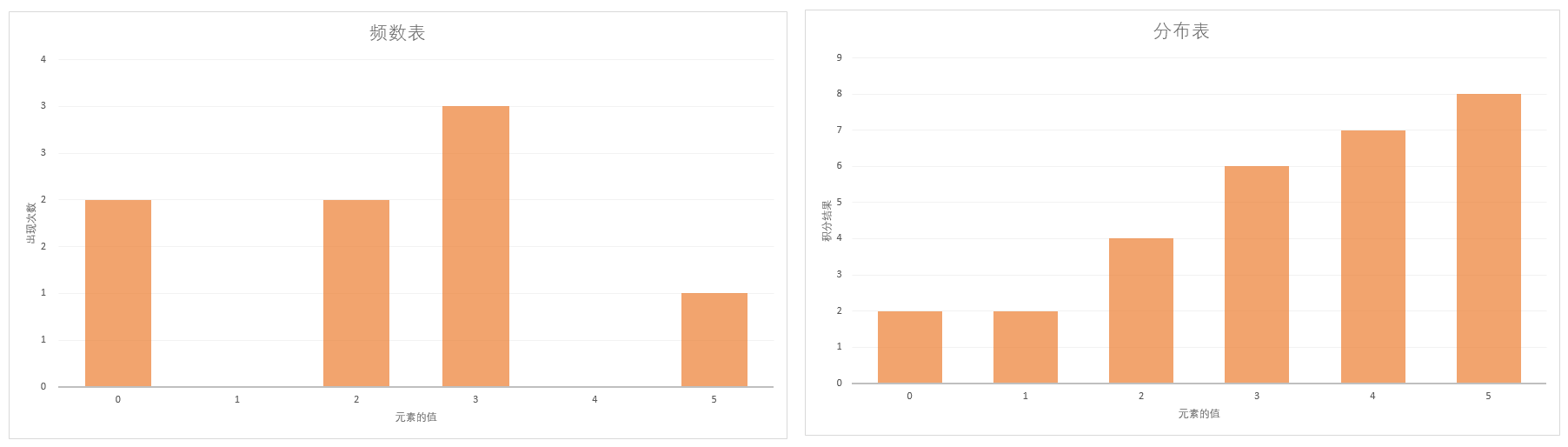
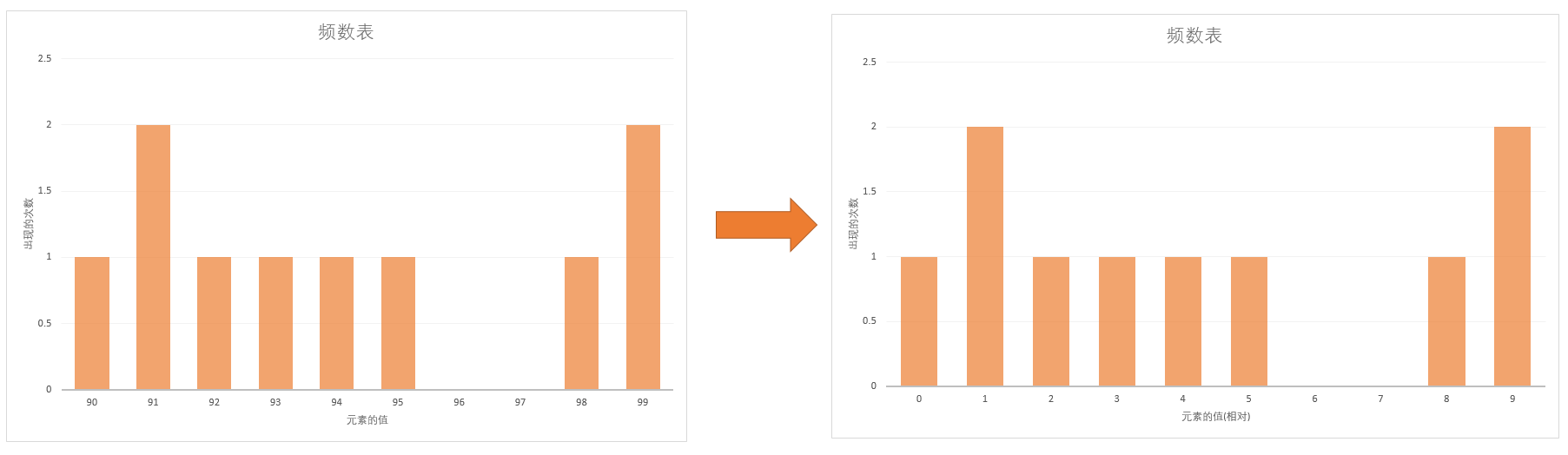
int *countingDistribution(int &startRange, int &len){ //Step 1. 计算分布表横坐标范围[minIdx, maxIdx] int minIdx, maxIdx; findMaxMinIdx(minIdx, maxIdx); len = A[maxIdx] - A[minIdx] + 1; startRange = A[minIdx];
//Step 2. 新建频数表,并初始化为0 int *distribution = newint[len]; memset(distribution, 0, len * sizeof(int));
//Step 3. 进行统计,注意x进行了平移,从startRange开始 for (int i = 0; i < n; ++i) { ++distribution[A[i]-startRange]; }
//Step 4. 统计求和,得到分布表 for (int i = 1; i < len; ++i) { distribution[i] += distribution[i-1]; } return distribution; }
intmain(){ //Step 1. 计算分布表 int srange, lenx; int *distrib = countingDistribution(srange, lenx);
//Step 2. 从分布表得到排序结果 int *result = newint[n]; for (int i = 0; i < n; ++i) { //根据分布表得到A[i]应该放在哪个地方 int &lastPosition = distrib[A[i]-srange]; //注意lastPosition是从1开始(逻辑序列),转成物理序列要减1 result[lastPosition-1] = A[i]; //放置 --lastPosition; //放置后地方-1,因为我们是从右边往左放置元素 }
//Step 3. 输出结果 for (int i = 0; i < n; ++i) { printf("%d ", result[i]); } delete[] distrib; delete[] result; return0; }
constint n = 10; int A[n] = {78,17,39,26,72,94,21,12,23,68}; vector<int> Bucket[10];
intmain(){ for (int i = 0; i < n; ++i) { //以第二位为主键放桶 Bucket[A[i]/10].push_back(A[i]); } for (int i = 0; i < n; ++i) { sort(Bucket[i].begin(), Bucket[i].end()); //对链表排序,任何一种排序方式都可以 //遍历输出 for (vector<int>::iterator iter = Bucket[i].begin(); iter != Bucket[i].end(); ++iter) { printf("%d ", *iter); } } return0; }